Vision-Language & Multimodal Models
Voice-over: ../assets/audio/mutlimodel.mp3
Newer research looks beyond recognizing paint on the road and tries to understand the whole scene. Vision-language models (VLMs) combine visual features with language prompts so they can describe context, explain decisions, and even rate whether it looks safe to cross. A recent study uses a large multimodal model (GPT-4V) to predict a street-crossing safety score and provide a short explanation [3].
VLMs can also help traditional perception by providing semantic context. In pedestrian detection, a CVPR’23 method (VLPD) leverages vision-language supervision to learn contextual cues (e.g., sidewalks, vehicles) without extra manual labels—improving results under occlusion and crowded scenes [4]. Surveys summarize broader applications across perception, planning, and decision-making, while noting open issues like latency, reliability, and domain shift [5].
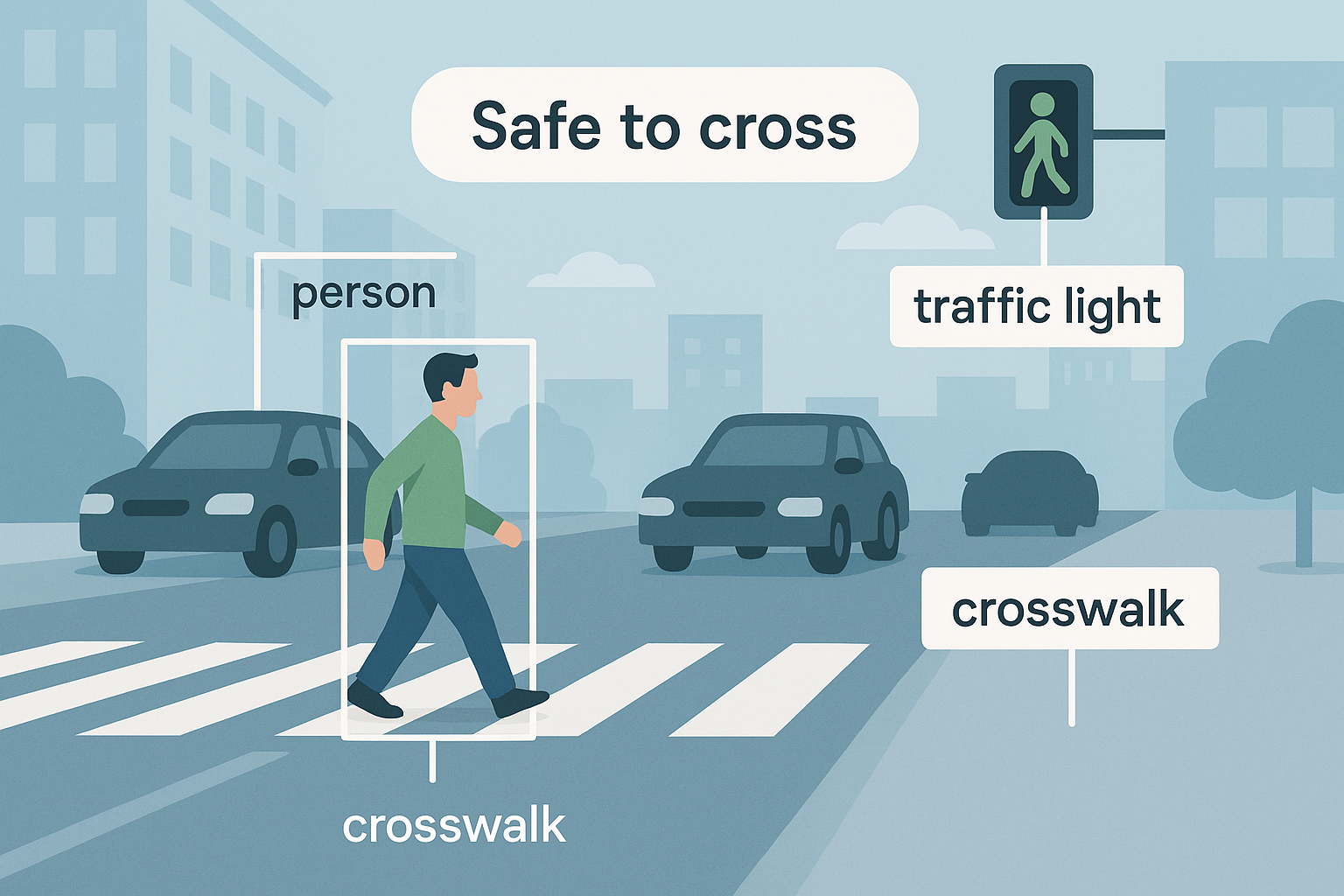
Why Multimodal?
- Brings context (signals, vehicles, pedestrians) into the decision.
- Supports language explanations useful for accessibility.
- Enables zero/few-shot adaptation via prompts.
Current Limits
- Latency & compute for real-time edge deployment.
- Hallucinations / inconsistent reasoning in hard cases.
- Domain shift (new cities/night scenes) still challenging.
Takeaway: multimodal models don’t replace classical or CNN-based detectors; they add contextual reasoning on top. A practical system can combine fast detectors with a VLM that explains or double-checks safety in harder scenes [3] [5].